



CVPR 2019 论文解读:人大 ML 研究组提出新的视频测谎算法 CVPR 2019
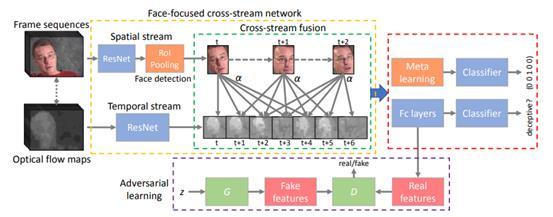
:计算机视觉顶会 CVPR 2019 即将于 6 月在美国长滩召开,今年大会共收到超过 5165 篇论文投稿,最终收录的论文为 1299 篇。随着会议临近,无论是学术界还是业界都迎来了一波 CVPR 2019 入选论文解读热潮。 今年的 CVPR 2019,卢志武博士领导的中国人民大学信息学院机器学习(ML)组共有 3 篇论文被录用,论文主题涵盖视频识别、小样本学习、视觉对话等热点问题,本文中要解读的论文便是其中关于视频识别的一篇:《面向视频测谎的聚焦人脸的跨帧双流网络》「Face-Focused Cross-Stream Network for Deception Detection in Videos」。 该论文提出了一种新颖的视频测谎算法,这种算法只需要少量的视频数据进行训练,并在训练后对短视频进行测试。实验结果显示,该测谎算法的准确率高达 90% 以上,同时在结合语音和 word2vec 信息后,这一准确率可以进一步提高至 95% 以上。 视频测谎,即是检测视频中的人物对象是否说谎。目前,视频测谎问题还面临着两大挑战:(1) 如何有效地融合面部和动作信息来判断视频中人物对象是否说谎;(2) 真实的视频数据集规模很小,如何将深度学习应用在数量有限的训练数据上。为了解决这两个问题,本文提出了 face-focused cross-stream network(FFCSN)模型(如图 1)。
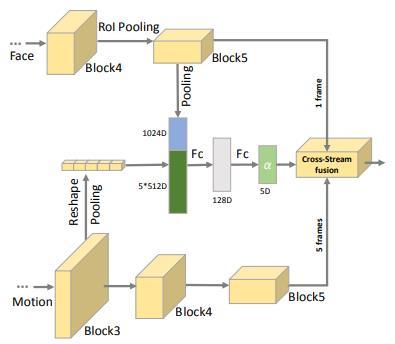
不同于常见的双流网络模型(two-stream network)利用空间流捕捉视频帧整体静态空间特征以及利用时间流捕捉视频光流动态特征的做法,FFCSN 模型考虑将人脸检测用于空间流来捕捉面部特征,并在整个网络中利用相关学习来融合时空特征进行联合训练。 同时,论文作者结合心理学知识(即说谎者由于紧张, 其面部表情和身体姿势往往会不一致),发现双流法中的图像特征和光流特征逐帧对应匹配并不是视频测谎的最优解决方案。因此,作者提出了跨帧的双流网络 (cross-stream network)——这种网络可以捕捉面部表情和身体姿势不一致的关系。利用这种网络,视频中的每一个面部表情帧都隔一定间距匹配五个光流帧,并让模型自动学出这五帧之间的权重关系。此外,论文作者还将时间流 ResNet 的 block3 使用全局池化层将其变为向量,使得模型经过两组全连接和一个 softmax 层后,能够学习到五个动作帧之间的权重关系。通过学习这个模块,模型具有了对不同的动作帧赋予不同权重的能力。
具体来说,该方法将每个视频分成 K 个片段,对于每一个片段,随机抽样一帧表情帧 和五个动作帧 (见图一橙色框处)。这样,对于每一个片段,可以得到如下数据: 其中代表这五个动作帧之间的权重, 的总和为 1。令代表模型对 的分类概率以及 代表对一个视频所有片段的平均分类概率,那么损失函数定义如下:
此外,FFCSN 模型还引入了元学习(meta learning)和对抗学习(adversarial learning)来解决训练数据量小的问题。元学习使用了 relation 的思想, 通过学习数据之间的关系来提高模型的泛化能力,而对抗学习在训练时使用生成的「假」特征向量攻击模型分类器来达到扩充数据量的目的。
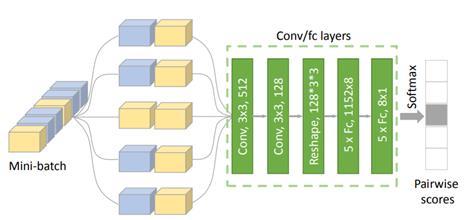
元学习模块的网络结构具体如图 3 所示。容易看出,模型从每个 mini-batch 中选出了两对六元组,每一对六元组中有两个样本来自同一类别,另外四个样本则来自不同类别。取相同类别的两个样本其中的一个作为 anchor,让它与另外五个配对组成五对数据,因此这样得出的结构就有一对类别相同的样本和四对类别不同的样本,接着在训练后,再由卷积和全连接层后对这五对数据进行分类,使模型能够选出类别相同的一对。结果证明,这种度量学习的思想对于小数据集上的增益十分明显。 对抗学习模块见图 1 紫色框的部分,此处是用 G(Generator)生成虚拟的 feature vector,之后用 D(Discriminator)进行判别以增强模型的鲁棒性,从而解决小样本的问题。损失函数和 GAN 类似,如下式所示:
由于模型由前面介绍的三个子模块组成,总的损失函数即为这三部分的加和。论文作者将这三部分联合训练,取得了不错的实验结果。 FFCSN 模型在公开的真实庭审视频数据集上取得了当前最好的结果,验证了该模型在视频测谎中非常有效, 实验结果也说明了说谎者在表情和动作上很容易出现不一致的问题。如图 4,说谎者在面部表情和第二帧光流匹配时有明显的下降,这种波动为模型判断说谎提供了依据。
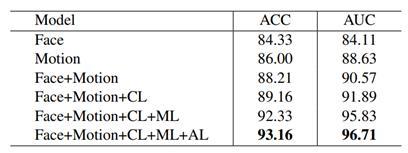
为了验证模型的不同模块均是有效的,论文作者进行多组消融实验。从表 1 可以看出,与只使用 face 或者只使用 motion 相比,同时利用面部和动作两个信息的模型所取得的效果有较大的提升。而在加入了 cross-stream 的匹配 (CL) 之后, 模型精度有了进一步的提升。此外,为了克服数据量过小的问题,,作者在模型中加入了元学习 (ML) 和对抗学习 (AL) 模块, 这些都对提高模型的鲁棒性有很大的帮助。
为了验证模型的扩展性,作者也在表情识别数据集上做了实验,,并在 youtube-8 数据集上取得了目前最高的精度。youtube-8 dataset 包括 1101 个视频,分为 8 种表情。从表 2 的实验结果可知,虽然作者只使用了 visual 单模态,但仍取得了准确率比其他使用更多模态 (语音和属性) 的方法高 5% 的好成绩。
中国人民大学信息学院机器学习(ML)组由卢志武博士,以及 20 名博士生与硕士生组成,隶属于文继荣教授的大数据分析团队。目前,人大 ML 组已经在 TPAMI、IJCV、NIPS、CVPR 等国际顶级期刊/会议上发表 40 余篇论文,主持了 NSFC、KJW 等多个国家科研项目,还曾获人工智能国际权威评测 ImageNet 2015 视频检测任务亚军。 |
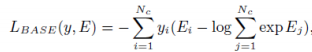
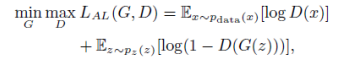








Archiver|手机版|小黑屋|
百度云会员 百度网盘会员 百度云盘会员 百度云会员账号共享
( 辽ICP备16014922号 )

GMT+8, 2025-10-8 15:24 , Processed in 0.039667 second(s), 8 queries , File On.